XML Resource Concepts
The
following documentation is available for XML and Web Service resources:
- Tutorial: Calling a Web Service is a tutorial designed to provide a quick introduction to using XML and Web Service resources. This is recommended as the place to start learning about XML and Web Services resources.
- Working with XML and Web Services Resources provides an overview of the facilities available using XML Resources and Web Service Resources.
- Creating and maintaining XML Resources explains how to use the studio to create and maintain XML Resources and Web Service Resources.
- XML Resource Adapters describes the supplied adapters and parameters to configure them.
- Web Service Adapter how to use the XML resource with a Web Service.
- XML Concepts gives some general information on XML.
This document provides in depth
technical information on XML Resources and Web Service Resources.
This documentation applies to both
XML Resources and Web Services Resources. The term XML Resource used
below applies to either an XML Resource or a Web Services Resource.
Overview
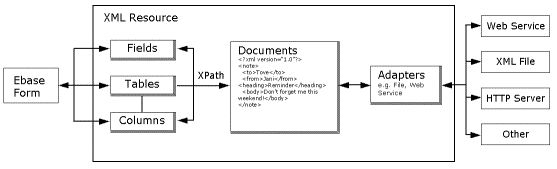
The diagram shows the basic building blocks of the XML Resource.
Documents – The resource designer can configure any number of documents, each one capable of holding a single XML document. In some situations, a single document may be sufficient. For example, a form may need to read XML from a file and display some of its values in a form. In other situations, multiple documents are required. For example, a web service resource will need an outbound request document and an inbound response document. Documents may also be set up for temporary data storage, for example, the result of an XSL transform.
Adapters – Perform operations on the documents. Often, this involves transferring XML documents to and from external sources. Adapters have been provided for some common backend technologies, such as web services and file systems. Other adapters work internally, moving XML between resource documents. Web Services Resources have a special Web Services Adapter and this is always created as the default adapter for these resources. See XML Resource Adapters for a full list of available adapters.
Fields, Tables, Columns – Provide Verj.io forms with access to the XML data. Fields are bound to a location within one of the documents using a technology called XPath. The form fields mapping dialog can then be used to map form fields to resource fields in the same way as other Verj.io resources.
XPath is a language used to identify particular parts of XML documents. With XPath you could, for example, write expressions that refer to:
- the
document's first
personelement - the seventh
child element of the third
personelement - the
IDattribute of the firstpersonelement whose contents are the string "Arthur Smith" - all
xml-stylesheetprocessing instructions in the document's prolog
and so forth. XPath indicates nodes by position, relative position, type, content, and several other criteria.
Web Services Example
This example describes how an XML resource would be configured to communicate with an imaginary web service that multiplies a supplied number a requested number of times.

The multiplying web service is invoked by a SOAP message containing, amongst other things, the number to multiply and how many times to multiply it. In response, it returns a SOAP message containing multiples of the supplied number.
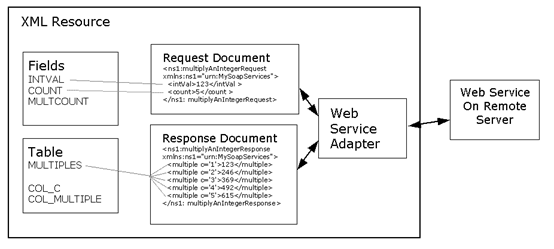
The diagram shows an example of how the XML
resource might be configured to call the web service. Two documents are
needed: a request and a response. A web service adapter is used to
communicate with the web service. The resource has three fields and
a table with two columns. Each is bound to one of the documents
using an XPath expression. Fields in the
form are mapped to their respective resource fields (not shown).
When a script command invokes the resource, form field values will be written into the request document at the location identified by their XPath expressions. The web service adapter will then embed the request document into a SOAP message and post it to the web service. If all goes well, the adapter can then pick up the response SOAP message, extract the XML body and set it as the resource's response document. The Verj.io form may then retrieve the table information using an FPL fetchtable command or API Table.fetchTable() method.
Documents
An XML resource may contain any number of
documents. Each document is identified by a unique name.
For example: a web service resource will
normally contain a least two documents, an outbound request document and an
inbound response document. It will probably also contain a fault
document, in case the web service returns a SOAP fault. The user
may also choose to set up additional documents to hold XML from manipulations
such as XSLT.
A document may optionally have an associated
structure. The structure is used to
organize the generated XML. Data is transferred from an
Verj.io form into XML documents using script commands
such as ‘update’ and ‘updatetable’. As
this occurs, the structure ensures correct ordering of XML elements and
attributes. Setting a structure is
recommended for all documents, but it is especially important for any document
receiving data from an Verj.io
form. If no structure is defined, then the ordering of XML elements is
uncertain. The structure is also very
useful when setting up resource fields.
Adapters
Verj.io ships with a number of XML resource adapters. It is hard to generalize about adapters because each performs a different task. Some transfer XML data between a remote location and a resource document. The file adapter is an example of this. Others, such as the web service adapter, can send one of the XML documents to a server and retrieve the XML reply into another. There are also adapters that move XML data internally within the resource. The XSL Transform and Copy adapters are both examples of this.
An XML resource may have any number of adapters, each identified by a unique name.
Each XML resource can have a single default adapter. The default adapter has no name, making it easier to call from a script command. Otherwise it is identical to other adapters.
Schema
An XML resource may have as many schema documents as necessary to describe the XML types it uses. These take the form of standard XML Schema documents as specified by the W3C. The types and elements defined in the schemas can be referenced by document structures.
A note about Imports and Includes
It is not possible to refer to an external schema using the import or include facility. All schemas must be defined within the resource itself. Import and Include XML schema tags are permitted, but the schemaLocation attribute refers to the name of another schema within the same resource.
Namespaces
Namespace prefixes can be defined for use in XPath expressions. They have no other use and have no effect on XML documents.
Any number of namespace prefixes can be defined, but they must be unique. It is possible to define multiple prefixes for a single namespace URI.
Example:
One of the documents contains some XML:
<three:element1 xmlns:one='http://ebasetech.com/schemaOne'
xmlns:two='http://ebasetech.com/schemaTwo'
xmlns:three='http://ebasetech.com/schemaThree'>
<one:element2>AAAA</one:element2>
<one:element2>BBBB</one:element2>
<two:element2>CCCC</two:element2>
<three:element2>DDDD</three:element2>
</three:element1>
This document declares three namespaces: http://ebasetech.com/schemaOne, http://ebasetech.com/schemaTwo and http://ebasetech.com/schemaThree.
The resource's namespaces could be set up as:
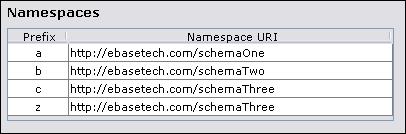
In which case the following XPath expressions point to the elements with the following values.
XPath Value
/c:element1/b:element2 CCCC
/a:element1/b:element2 invalid there is no element1 in http://ebasetech.com/schemaOne
/c:element1/c:element2 DDDD
/c:element1/z:element2 DDDD z points to the same namespace URI as c
Tables and Fields
XPath
XML resources use XPath to tie fields to XML data. XPath is an XML standard used to identify a location within an XML document.
For example:
Given the
following XML document:
<element1>
<element2>
<element3>value1</element3>
<element4 attribute1=”value2”/>
<element4 attribute1=”value3”/>
<element4 attribute1=”value4”/>
</element2>
</element1>
/element1/element2/element3 is an XPath expression that locates the single element3 element.
/element1/element2/element4 is an XPath expression that locates the three element4 elements.
/element1/element2/element4[@attribute1=’value4’] is an example of an XPath that locates the last element4.
XPath variables
XPath expression may also contain variables. The standard '$' XPath notation is supported, where the variable value is taken from another resource field. It is also possible to build XPath expressions dynamically using the '&&' notation. The value of a form field could contain a value for comparison, a piece of an XPath query or even the whole XPath query.
Example:
1. In the above XML document, the XPath expression /element1/element2/element4[@attribute1=$INVAR] could be used to dynamically find one of the elements called element4 depending on the value of INVAR. If INVAR evaluated to value2 then the first element4 would be found. In an XML resource, the value is taken from another resource field, so in this case there should be field called INVAR. If the field is only used as a variable, it should be set as unbound.
2. The same result could be achieved using the '&&' notation: /element1/element2/element4[@attribute1='&&INVAR']. In this case though the variable needs to surrounded by single quotes. More interestingly, whole expressions or part expressions can be substituted. The XPath could be set as /element1/&&QUERY. A script could then build up the rest of the expression. (e.g. SET QUERY = ‘element2/element4’;)
It is also possible to have an XPath expression that returns a calculated value rather than an XML node location. The count function is an example of this.
Example: count(//element4) returns a count of the number of elements called element4. In this case it would be 3. A resource field set up like this would probably map to an integer form field.
The examples show just a subset of things that XPath is capable of. Please refer to one of the many guides to XPath for more information.
Read only
Fields and Tables may be marked as read only. If this is the case, data will only flow from the XML document into the form. The field or table will never be used to write values into the XML document. This feature is essential when using complex XPath expressions where a destination node would be impossible to locate.
Unbound
Resource Tables and Fields are bound to XML by identifying a document and an XPath. If the document is omitted, the field will be considered unbound. Unbound fields are useful when used as input variables in XPath expressions because values are neither read nor written to XML. They are, however, still available for use as variables in XPath expressions. When used as an XPath variable, the value is obtained via a mapping to a form field.
Fields
A field represents a single value in an XML document. Resource fields can be mapped to form fields in exactly the same way as other Verj.io resources.
Each time a field value is accessed or modified via a script command, the field’s XPath expression is evaluated on the field’s document. If the XPath expression successfully locates an XML node then its value will be selected or updated.
Resource fields are intended to have a single value. Therefore, it is anticipated that a field's XPath expression will evaluate to a single simple XML node. Owing to the flexible nature of XPath, this may not always be the case. If the expression results in multiple nodes, then the first node in the document will be used.
When writing field values into XML, if the destination location does not already exist, then it will be created. In this situation, only the simplest of XPath expressions can be dealt with. The algorithm used to do this is as follows:
- The last child is trimmed from the expression (at the last '/').
- The new expression is executed.
- Steps 1 & 2 continue until the expression successfully locates an existing node.
- The trimmed names are then revisited in reverse order. For each, a new element is added to the XML document.
It is best to stick to "child" and "attribute" XPath axes when making a writable field (e.g. element1/element2/@attributeA).
Tables
Resource tables are also bound to a specified document using an XPath expression. In contrast to resource fields, it is anticipated that the XPath expression will evaluate to multiple nodes. Each resultant node represents a separate row in the table. Column values are evaluated by executing relative XPath expressions on each table node.
For example:
Given the
following document:
<element1
attribute0="title">
<element2>
<element3>value1</element3>
<element4 attribute1=”value2”/>
<element4 attribute1=”value3”/>
<element4 attribute1=”value4”/>
</element2>
</element1>
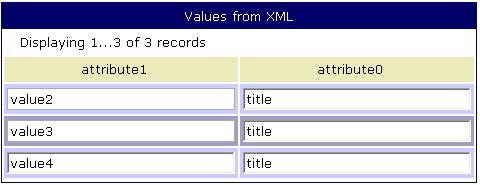
A table has an XPath expression of element1/element2/element4.
It has two columns with XPath expressions @attribute1 and ../../@attribute0.
The table's XPath finds all three element4 nodes. Therefore the table will contain three rows. Then for each row, two column XPaths will be executed. The first column gets the value of attribute1 ('@' is the XPath notation for an attribute). The second XPath steps back up the hierachy twice and gets the value for attribute0. This value will be the same for all three rows because all three element4's have the same parent element.
When inserting new rows into a table, the table's XPath must be simple enough to determine the location of a new element and the type of element to insert.
When adding a new row, the XPath is split at the last '/'. The path preceding the '/' determines the location of the new element. The text after the '/' is used as the type of the new element. There is therefore a limit to how complex the XPath can be for a writable table:
The XPath should terminate with a '/' followed by an element name. (including the namespace prefix if necessary). The rules for the expression preceding the last '/' are the same as field XPaths.